Raja CHIKY
Research
[Data Stream mining] [Recommender Systems] [Cloud computing] [Peer To Peer]
Phd Supervision
- Sylvain Lefebvre, 2010-2013 (Phd director: Mr Eric Gressier-Soudan, CEDRIC CNAM)
Topic: Montée en charge des application multimédia dans une architecture cloud - Sathiya Prabhu Kumar, 2012-2015 (Phd director: Mr Eric Gressier-Soudan, CEDRIC CNAM)
Topic: Adaptation de la cohérence de données répliquées en fonction du profil applicatif dans une architecture à haut degré d’élasticité - Fethi Belghaouti, 2013-2016 (Phd director: Mrs Amel Bouzeghoub, INT Sud telecom)
Topic: Interopérabilité des systèmes distribués produisant des flux de données sémantiques au profit de l'aide à la prise de décision - Manuel Pozo, 2013-2016 (Phd director: Mrs Elisabeth Métais, CNAM)
Topic: Towards Accurate and Scalable Recommender Systems - Rayane El Sibai, 2015-2018 (collaboration with Université de Liban)
Topic: Raisonnement dans un contexte de streaming : Interconnexion et qualification des flux - Georges Chaaya, 2016-2019 (Phd director: Mrs Elisabeth Métais, CNAM, collaboration with Université de Liban)
Topic: Apprentissage actif de filtrage collaboratif pour les systèmes de recommendation – Résolution du problem de démarrage à froid - Denis Maurel, 2015-2018
Topic: Apprentissage automatique multi vue
Cloudizer: a Java middleware layer for Cloud Computing ▲
Keywords : Load Balancing, cloud, web services, etc.
Abstract :
CLOUDIZER is a software load-balancing framework for web services. It aims to balance efficiently and transparently the load of REST-based web services. The goal is to allow transparent deployment of legacy applications on scalable infrastructures such as Infrastructure as a service clouds.
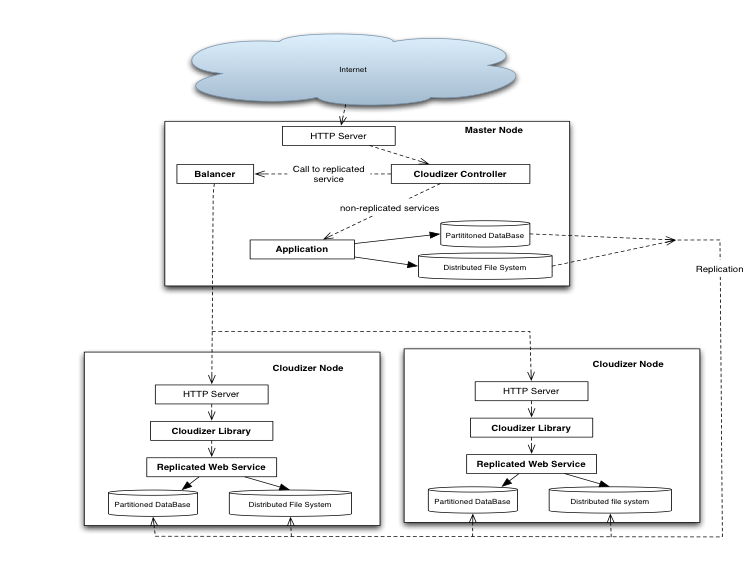
As shown in the figure, the CLOUDIZER controller deployed on the master node, which filters the requests, achieves load distribution. When the master receives a request, it forwards this request to the target application according to a load balancing policy configured by the user. Since the goal of this framework is to achieve transparent load balancing, application code and data files are replicated among the nodes through a distributed file system.
Slave Nodes register the deployed applications to the master. These nodes are monitored by sending a heartbeat to the master node. Using CLOUDIZER framework, any load-balancing policy can be applied for the target application, depending on the user's needs to get advantage from it.
Different load-balancing policies can be applied depending on the users needs, and each application can be configured to use a different load balancing policy.
A Java Application Programming Interface is used for implementing new policies and the user just needs to provide the policy name in a configuration file to use the policy.
https://forge.isep.fr/projects/isep-cloud/;
Simizer: Simulation for cloud based application distribution▲
Keywords : Load Balancing, cloud, web services, etc.
Abstract :
The goal of SIMIZER is to provide a way to evaluate and measure the behavior of cache memory optimization, different load balancing, and/or consistency policies regarding different measure such as response time, latency, throughput, locking, and complexity. The goal is to provide a simple way to implement and test algorithms, without the caveats of real world experimentation on large platforms.
The motivation behind this work is the need of a simple and reliable testing framework for large (> 100 machines) distributed systems load balancing and consistency / data synchronization protocols. Existing frameworks such as SimGrid, GridSim and CloudSim do not provide ways for simulating data consistency issues in large-scale systems. Regarding load balancing, these simulators mainly aimed to provide information regarding the platform-side behavior (load on machines, power consumption, CPU utilization, throughput). However we consider important to obtain results from a user / client perspective regarding metrics such as perceived latency and algorithms practical performance on realistic workloads.
SIMIZER is a trace-based discrete event simulator. To generate the traces, the user can specify different random laws to define the parameters distributions, bandwidth allocation, requests frequencies, and number of available machines. This document describes in a first part how to use the SIMIZER program and interpret its output.
https://forge.isep.fr/projects/simizer/;
Summarizing distributed data stream ▲
Keywords : Distributed Data Streams, adaptative sampling, sensors, interpolation, load curves
Abstract :
Remote sensing enables data collection from multiple sources in a unique
central server for a large wide of applications which are typically monitoring and
system supervision, transmitting alarms in real time and more generally producing
synthesis to help in business decision. The volume of data collected is generally too
big to be stored entirely. Data Stream Management Systems are generic tools for
processing data streams : data elements arrive on-line and stay only for a limited
time period in memory. For many stream processing applications, one may not wish
to completely lose the entire stream data for analyzing 'past' and 'present'data. Thus
a stream processing system must also provide a stored historical data.
In this thesis, we consider a distributed computing environment, describing a
collection of multiple remote sensors that feed a unique central server with numeric
and uni-dimensional data streams (also called curves). The central server has a limited
memory but should be able to compute aggregated value of any subset of the
stream sources from a large time horizon including old and new data streams. Two
approaches are studied to reduce the size of data : (1) spatial sampling only consider
a random sample of the sources observed at every instant ; (2) temporal sampling
consider all sources but samples the instants to be stored. In this thesis, we propose
a new approach for summarizing temporally a set of distributed data streams : From
the observation of what is happening during a period t - 1, we determine a data
collection model to apply to the sensors for period t.
The computation of aggregates involves statistical inference in the case of spatial
sampling and interpolation in the case of temporal sampling. To the best of our
knowledge, there is no method for estimating interpolation errors at each timestamp
that would take into account some curve features such as the knowledge of the
integral of the curve during the period. We propose two approaches : one uses the
past of the data curve (naive approach) and the other uses a stochastic process for
interpolation (stochastic approach).
Recommender System for SoliMobile ▲
Keywords : Open source recommender systems, collaborative filtering, Mahout, Web usage mining
Abstract :
The project SOLIMOBILE is funded by ProximaMobile and aims to design, build and implement
a package of innovative services focused on the person in a precarious situation.
The group of partners includes Les Cités du Secours Catholiques who are in charge of identifying
the requirements, testing and using the developed services, ISEP which provides expertise and
Research on personalization and adaptation to user profile and participates in developing services,
iEurop and Streamezzo who bring their technologies, their capacity for hosting and development,
and Atos Origin Integration coordinating and supporting all the development effort.
ISEP, through its expertise in information retrieval and data mining proposes to explore and evaluate on real data (SOLIMOBILE databases) algorithms for:
- Data preprocessing, which includes merging of log files, cleaning, structuring and aggregation of data. This step will reduce the amount of data relevant to the understanding of user profiles and provides structured data for the next stage of data mining;
- Detecting similar users behaviour from large preprocessed data to build users profiles that will be associated to sets of offers and services. Hybrid algorithms will be implemented and will involve classification algorithms, machine learning, association rules, complex data mining, etc.
- Taking into account the variation of data. Indeed, most data mining algorithms assume that models are static and do not take into account the possible evolution of these models over time. ISEP propose to dynamically change the model implemented in the framework of SOLIMOBILE to reflect behaviour of visitors and adapt the content of the platform (by modifying offers and services for example).
Definition and dissemination of semantic signatures in Peer-to-Peer▲
Keywords : semantic P2P, Bloom Filter
This work was completed under the project RARE.
Abstract : Peer-to-peer systems (P2P) have become popular with sharing files on Internet. Much research has emerged concerning the optimization of data localization, and constitutes a very active research area. Taking into account semantic aspects improves considerably data localization. We based our study on the PlanetP approach, which uses the notion of Bloom Filter consisting on propagating peers' semantic signatures (Bloom Filters) through the network. We extend this approach with some improvements such as the creation of dynamic Bloom Filters, their size depends on the load of peers (number of shared documents).